- Tech Corner
- Articles
- ms sql server
Troubleshoot SQL Server Locking
Abstract
Locking Basics
In short, locking is the mechanism of preventing multiple requests from making simultaneous changes to the same data. In SQL Server, and to simplify, a request is made by a connection, which is viewed on the server as a process. A process is identified by its unique ID called process ID or spid. For the purpose of this article, the term process is used for connection, transaction and session.
Locks
SQL Server offers different levels of locking or granularities. They are presented in table 1 below.
| Locks | Description |
|---|---|
| RID KEY |
Row identifier (RID) is used to lock a single row within a table. KEY is used to lock a single row within an index. |
| PAG | Data page or index page lock. |
| TAB | Lock on an entire table, including all data and indices. |
| DB | Lock on the entire database. |
In addition, SQL Server defines different modes of lock [4]. A lock mode determines whether a lock can be shared between processes. Table 2 describes the commonly seen modes; the complete list of lock modes is described in [4].
| Modes | Description |
|---|---|
| Shared (S) | Used for read-only operations such as SELECT, it allows multiple processes to access the same data. |
| Exclusive (X) | Used for data-modification operation such as INSERT, UPDATE or DELETE, it ensures exclusive access to a resource by a given process. |
| Update (U) | Used on resources that can be updated. It is used mostly for preventing deadlock resulting from reading then updating resource [1]. |
It is important to understand the compatibility between different lock modes [1]. That is, if process A has acquired a lock on a given resource in mode m and process B request a lock on the same resource in mode n, the lock is granted to B only if n is compatible with m. This knowledge will come handy when troubleshooting.
Lock Escalation
The finer are the locks, the more concurrency is permitted, but the database must work harder to keep track of the bigger number of locks. Using coarser locks will incur less overhead for the database, but the degree of concurrency is also lesser.
Lock escalation is the process of converting many fine-grain locks into fewer coarse-grain locks, thus reducing the system overhead. SQL Server automatically escalates row locks and page locks into table locks when the number of locks in a transaction exceeds the escalation threshold.
Deadlock & Blocking
Deadlock occurs when a process holds a lock on resource A and tries to acquire a lock on resource B, while another process already holds a lock on resource B and tries to acquire a lock on resource A. All databases that I have worked with, including SQL Server, detect such deadlocks and resolve them by arbitrarily killing one of the processes involved.
Blocking in SQL Server occurs when a process tries to acquire a lock on a resource that is incompatible with an existing lock on the same resource. For instance, process P1 reads the content of a table and puts a shared lock S on it. Now process P2 wants to update some rows in the same table and tries to acquire an exclusive lock X. Since X is incompatible with S [4], P2 will be blocked by P1 until the latter finishes reading the table and releases its shared lock.
Blockings may hide deadlock problems involving foreign code, that is, code of an application running outside of SQL Server. For instance, an application may have two threads T1 and T2, both have a connection to the database. The connection from T1 holds a lock on a resource R and T1 waits for some results from T2. In the meantime, the connection from T2 is blocked from that of T1, preventing it from returning the results expected by T1. Such deadlocks cannot be detected by the database, thus cannot be automatically resolved. In the following sections, I will show how to troubleshoot such deadlocks.
Finding the Problem
In order to fix a problem, we need to know what the problem is and where it lies. There are many ways to find locking and blocking issues in SQL Server [5]. In this section, I will show one way to identify the cause of a blocking problem.
The Symptoms
After the initial port to SQL Server, the application seemed to run fine, until we started stress testing. When running against hundreds of thousands of records, the application hangs. Java threads dumps did not show any java deadlock, but show some threads stuck on reading from the database. The problem was thus somewhere in the database.
Leaving the application hung for a long time did not yield to deadlock resolution by SQL Server (at first the testers did not suspect a hanging problem; they thought the queries were running slow because of the amount of data, so they left it run overnight). Therefore, it must be a blocking problem involving Java code.
Identifying the Cause
An easy and quick way to find out a blocking issue is to use SQL Server Enterprise Manager (EM) or SQL Server Management Studio (SMS). For example, figure 1 shows the information revealed by Management –> Current Activities –> Process Info in EM during my troubleshooting. In SMS, the same information can be seen under Management –> Activity Monitor | View Processes.
 |
Figure 1 shows that process 51 is blocked by process 52 on a SELECT statement (the blocking information is shown under Locks / Process ID in figure 1; it is also available under Process Info, but clipped out from the figure). Process 52, however, is "awaiting command"; this means that it is idled, waiting for something. Process 51 and 52 are two different sessions (i.e. connections) from the same application. But it still does not tell why and where the application hangs.
Another piece of information can be obtained from the stored procedure sp_lock. Figure 2 shows the result of executing sp_lock in SQuirrel. It indicates that process 51 tries to acquire (status WAIT) a shared lock on page 1:3458, which is incompatible with the intent exclusive (IX) lock that process 52 already holds (status GRANT) on the same page. That explains why process 51 is blocked by process 52.
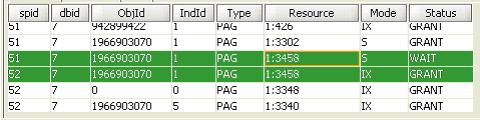 |
Note the type of the lock (row, page, table etc.) and the mode of the lock (shared, exclusive etc.) as they help choosing an appropriate resolution. Under EM or SMS, the lock type and mode are under Wait Type [3] and Resource.
Note also the ObjId column for both processes in figure 2; that is the ID of the table where the blocking occurs. In order to find out the name of that table, the below T-SQL code can be used:
sql> declare @qualified_name nvarchar(512)
sql> exec sp_MSget_qualified_name 1966903070, @qualified_name output
sql> select @qualified_name
The table name, along with the threads dump, tells me the area in the code I need to look at. Finally, I found out that at some point, the application makes an update on a record in table T in one thread. In order to complete that update, it needs to do some queries on that same table T in a second thread. The operation in the first thread will not complete until the result of the SELECT in the second thread returns. But as previously seen, the SELECT tries to acquire an incompatible lock with the one already held by the first thread. Thus the second thread never returns and the application hangs in a deadlock that cannot be detected by the database. With a small set of data, the chances that both threads hold incompatible locks on the same page is small, therefore the application worked fine.
Resolving the Problems
Now that we know why the application hangs, it is just a matter of choosing the appropriate solutions among the many available [2][6].
Using Row Lock
Some times, blocking can be caused by the use of too coarse locks (i.e. page or table locks). In which case, you can resolve it by forcing row level locks by using the ROWLOCK hint [7] or sp_indexoption.
The ROWLOCK hint only applies to the query that uses it. For instance, the below statement instructs SQL Server to use a (shared) row lock only on the record(s) read by the query.
SELECT * FROM authors WITH (ROWLOCK) WHERE auth_id IN (1,2,4);
On the other hand, sp_indexoption tells SQL Server to always use row locks on the tables or indices you specify. For instance, you can use either of the two below statements to impose row locks on the authors table.
sp_indexoption 'authors', 'AllowRowLocks', TRUE sp_indexoption 'authors', 'AllowPageLocks', FALSE
Note that sp_indexoption does not prevent table lock escalation.
No Lock
If there is no lock, there cannot be any lock contention! The NOLOCK hint can be use to tell SQL Server not to use any lock from the query that specifies it. Unfortunately, the NOLOCK hint also means dirty reads, that is, it allows uncommitted data to be read.
For applications where dirty read is not acceptable, READPAST hint might be a viable solution. The READPAST hint does not prevent SQL Server from using shared locks, but it allows the SELECT to skip (read past) locked records. The side effect of READPAST is if a process is updating a record and you try to read that record, your SELECT will return empty.
Frequent Commit
One way to avoid lock contentions is to keep the running transactions short. But when you run queries on tens of millions of records, it can be difficult to keep the transactions short. So what to do in such case?
Well, one way is to keep modification transactions only as long as necessary. For instance, in our application, a java thread logs its operation (by inserting a record in the log table), then runs the operation (a very long query) in the same transaction, before committing everything at the end. Occasionally, the operation would lock up with EM reporting some blocked processes. It turned out that if a count(*) on the log table happened to be run during that operation, it puts a shared lock on the records it reads and gets blocked by the exclusive lock of the log record inserted at the beginning. Meanwhile, the processing of the long query (the operation) is done by other java threads that also need logging, but get blocked by the shared locks from count. Therefore, the operation can never finishes. There is no reason to keep the first logging in the long running transaction of the operation (we still need to log the operation whether or not that operation fails). Making that logging in a separate (short live) transaction solved this problem.
Another way is to use temp tables to avoid lock contentions. For instance, you might have a long running query on a table and the processing of that long query involves updates to the same table that might cause lock contentions. In that case, you can dump the result of the long query into a temp table, then process from that temp table so that there is no lock contention when updating the original table. Of course, temp tables have their own issues and limitations, but that is out of the scope of this article.
Read Committed Snapshot
With SQL Server 2005, a READ_COMMITTED_SNAPSHOT isolation level can be used to solve most of the blocking problems. Basically, a read sees the data as they are at the beginning of the transaction (last committed snapshot), so that it does not need to put locks on them, thus avoiding lock contentions and resulting in better performances.
-- check whether read_committed_snapshot is on SELECT name, is_read_committed_snapshot_on FROM sys.databases -- set read_committed_snapshot ALTER DATABASE <databasename> SET READ_COMMITTED_SNAPSHOT ON
The drawback is that SQL Server has to manage different versions or snapshots of the data, thus requiring more disk space and memory. But that is a small price to pay (literally) to avoid the headaches associated with lock contentions.
Conclusion
As you can see, there are many ways to remediate locking issues with SQL Server. But one of the most important task, and often the most time consuming task in those situations, is determining the root cause of the locking issues. Once the root cause is known, appropriate solutions can be applied. With SQL Server 2005, the read committed snapshot isolation level helps avoiding most of the locking issues.
References
- [1] Advanced SQL Server Locking
- [2] Lock Contention Tamed
- [3] Wait Types
- [4] Understanding SQL Server 2000 Locking
- [5] Understanding and Resolving Locking Problems
- [6] Reducing Locks
- [7] SQL Server 2000 Table Hints
Further Readings
FIX: lock esacalation in a scan
How to resolve blocking problems that are caused by lock escalation in SQL Server
Copyright © 2006, Northwest Summit. All rights reserved.
No part of this page may be reproduced, republished or copied without the
express written permission of its author.